
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- DDL
- 재정의
- 조합
- 열 속성
- jpa
- Exception
- equals
- java
- docker
- select_type
- hashcode
- AOP
- 인덱스
- 테스트 코드
- static
- DI
- stream
- StringBuilder
- VUE
- Spring
- SQL
- Test
- lambda
- jwt
- MSA
- KEVISS
- 필드 주입
- cache
- redis
- 생성자 주입
- Today
- Total
백엔드 개발자 블로그
정규화 본문
정규화란?
하나의 릴레이션에 하나의 의미만 존재하도록 릴레이션을 분해하는 과정이며,
데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성을 위한 방법입니다.
정규화의 목적?
다양한 목적이 있지만, 대표적으로 두 가지가 있습니다.
첫째, 불필요한 데이터 (data redundancy)를 제거해 불필요한 중복을 최소화한다.
하나의 테이블에 모든 정보를 다 넣게 된다면, 동일한 정보들이 불필요하게 중복되어 저장될 수 있습니다.
둘째, 삽입/갱신/삭제 시 발생할 수 있는 각종 이상 현상(Anomaly)을 방지하기 위해서,
테이블의 구성을 논리적이고 직관적으로 한다.
그 외에 DB 구조 확장 시 재디자인을 최소화, 다양한 관점에서의 query를 지원하기 위해서 등등의 목적이 있습니다.
정규화의 과정

정규화는 1 정규화 ~ 6 정규화 까지 여러 과정이 존재하지만, 실제로 보통 1 ~ 3 정규화까지의 과정을 거치게 된다고 합니다.
정규화 과정부터는 망나니개발자 님의 글을 옮겨왔습니다.
[ 제1 정규화 ]
제1 정규화란 테이블의 칼럼이 원자 값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것입니다.

위의 테이블에서 추신수와 박세리는 여러 개의 취미를 가지고 있기 때문에 제1 정규형을 만족하지 못하고 있습니다.
그렇기 때문에 이를 제1 정규화하여 분해해야 합니다. 제1 정규화를 진행한 테이블은 아래와 같습니다.

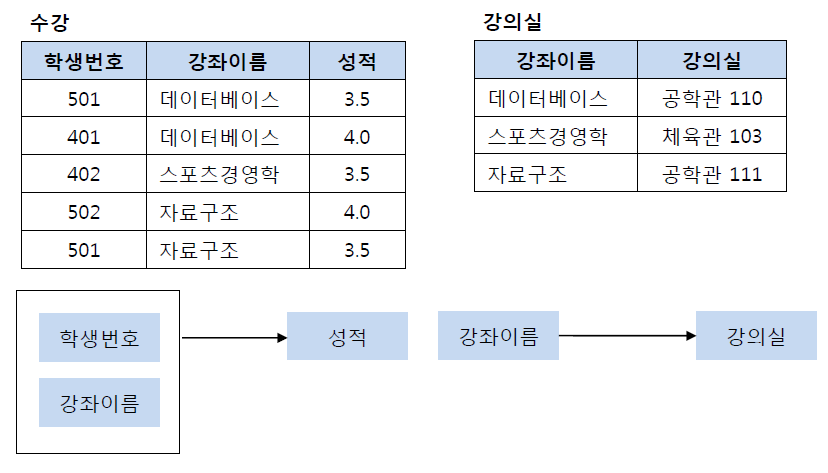
[ 제2 정규화 ]
제2 정규화란 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것입니다.
여기서 완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미합니다.

위의 테이블에서 기본키는 (학생번호, 강좌이름)으로 복합키 입니다.
그리고 (학생번호, 강좌이름)인 기본키는 강의실을 결정하고 있습니다. (학생번호, 강좌이름) → (강의실)
그런데 여기서 강의실이라는 컬럼은 기본키의 부분집합인 강좌이름에 의해 결정될 수 있습니다. (강좌이름) → (강의실)
또한 성적이라는 컬럼은 기본키의 부분집합인 학생번호에 의해 결정될 수 있습니다. (학생번호) → (성적)
그렇기 때문에 위의 테이블의 경우 다음과 같이 기존의 테이블에서 강의실을 분해하여 별도의 테이블로 관리하여
제2 정규형을 만족시킬 수 있습니다.
[ 제3 정규화 ]
제3 정규화란 제2 정규화를 진행한 테이블에 대해 이행적 함수 종속을 없애도록 테이블을 분해하는 것입니다.
여기서 이행적 함수 종속은 A → B , B → C가 성립할 때 A → C가 성립되는 것을 의미합니다.

위의 테이블에서 학생번호는 강좌이름을 결정하고 있고, 강좌이름은 수강료를 결정하고 있습니다.
그렇기 때문에 (학생번호, 강좌이름) 테이블과, (강좌이름, 수강료)테이블로 분해해야 합니다.
이행적 함수 종속을 제거하는 이유는 간단합니다.예를 들면 501번 학생이 강좌를 스포츠경영학으로 변경하였다고 하였을 때,
이행적 함수 종속이 존재한다면 501번 학생은 스포츠경영학이라는 강좌를 20000원이라는 수강료로 듣게 됩니다.
물론 수강료를 직접 바꿀 수 있지만, 이러한 번거로움을 해결하기 위해 제3 정규화를 하는 것입니다.

[ BCNF 정규화 ]
BCNF 정규화란 제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것입니다.

특강수강 테이블에서 기본키는 (학생번호, 특강이름)입니다. 그리고 (학생번호, 특강이름)은 교수를 결정하고 있습니다.
또한 여기서 교수는 특강이름을 결정하고 있습니다.
그런데 문제는 교수가 특강이름을 결정하는 결정자이지만, 후보키가 아니라는 점 입니다. 그렇기 때문에 BCNF 정규화를
만족시키기 위해서 위의 테이블을 분해해야 하는데, 아래와 같이 특강신청 테이블과 특강교수 테이블로 분해할 수 있습니다.

좋은 관계형데이터베이스를 설계하는 목적 중 하나가 정보의 이상 현상(Anomaly)이 생기지 않도록 고려해 설계하는 것입니다.
이상 현상은 테이블을 설계할 때 잘못 설계하여 데이터를 삽입, 삭제, 수정할 때 논리적으로 생기는 오류를 말합니다.
이상 현상은 갱신 이상(Modification ANomaly), 삽입 이상(Insertion Anomaly), 삭제 이상(Deletion Anomaly)으로 구성됩니다.
아래의 표를 예로 이상 현상에 대해 알아보겠습니다.
| 학번 | 이름 | 나이 | 성별 | 강의코드 | 강의명 | 전화번호 |
| 1011 | 이태호 | 23 | 남 | AC1 | 데이터베이스 개론 | 010-2627-8123 |
| 1012 | 강민정 | 20 | 여 | AC2 | 운영체제 | 010-4665-1941 |
| 1013 | 김현수 | 21 | 남 | AC3 | 자료구조 | 010-5223-4464 |
| 1013 | 김현수 | 21 | 남 | AC4 | 웹 프로그래밍 | 010-5223-4464 |
| 1014 | 이병철 | 26 | 남 | AC5 | 알고리즘 | 010-6305-2912 |
1. 삽입 이상 : 자료를 삽입할 때 의도하지 않은 자료까지 삽입해야만 자료를 테이블에 추가가 가능한 현상
강의를 아직 수강하지 않은 새로운 학생을 삽입할 경우 강의 코드와 강의명 속성에는 null값이 들어가야 하는 문제가 생깁니다.
2. 갱신 이상 : 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
강의 코드가 "AC3"인 김현수의 전화번호를 수정할 경우, 3번째 튜플의 데이터만 수정될 것입니다.
그러면 3, 4번째 튜플은 같은 사용자의 데이터임에도 불구하고 전화번호가 다르게 됩니다.
3. 삭제 이상 : 어떤 정보를 삭제하면, 의도하지 않은 다른 정보까지 삭제되어버리는 현상
강의코드가 "AC1"인 데이터베이스 개론 강의를 삭제하게 되면, 이태호 학생의 데이터까지 삭제되어버립니다.
이러한 이상 현상을 예방하고 효과적인 연산을 하기 위해 데이터 정규화(Data Normalication) 를 합니다.
'DB' 카테고리의 다른 글
| SQL vs NoSQL (0) | 2024.05.10 |
|---|---|
| Index (0) | 2024.05.10 |
| 동시성 제어 (1) | 2024.03.18 |
| SQL (0) | 2023.08.20 |
| RDBMS vs NoSQL (0) | 2023.08.18 |
